24 Abr 2023 Extracción de conocimiento de los datos de Airbnb en R
La evolución de la tecnología nos ha permitido poder almacenar cantidades abundantes de datos sobre cualquier ámbito. La información es uno de los recursos más demandados y la explotación de los datos requiere de perfiles bien instrumentados y capacitados como bien pueden ser los científicos de datos. En este post veremos la primera parte sobre la extracción de conocimiento de los datos de Airbnb en R. Esta extracción la podemos dividir en diferentes fases: la lectura, el preprocesamiento, el EDA y el análisis predictivo. Para más información sobre estas etapas podéis mirar este artículo de U. Fayyad.
El lenguaje de programación que usaremos será R. Para explicar cada etapa utilizaremos un proyecto que hemos realizado y que podéis ver aquí. En este post, no detallaremos cada paso, así que si quieres ver todo el código puedes dirigirte al enlace. Pero no te preocupes porque hemos destacado aquellos apartados del proyecto que son más interesantes de ver.
El esquema que seguiremos para esta primera parte será el siguiente:
- Lectura
- Preprocesamiento
- Visualización y filtrado de datos
- Reducción de características: calcular P(AyB)
- Extraer determinados valores con expresión regular
- Agregar y obtener la media de reseñas por barrio
- Obtener la valoración sobre la localización del inmueble
- Conclusiones
Antes de nada, deberíamos proponernos un objetivo y entender que datos tenemos en nuestras manos. Para realizar esta primera aproximación realizaremos una lectura de los datos que disponemos.
Lectura
Entender el significado de los datos, ver como se distribuyen y localizar inconsistencias es una de las tareas principales que se debe tener en cuenta en la etapa inicial de un proyecto. Con una lectura previa de las variables podremos hacernos una primera idea del trabajo que tendremos por delante.
Introducción del dataset
Introduzcamos el dataset con el que trabajaremos.
Los datos con los cuales se va a trabajar corresponden al registro de anuncios publicados en Airbnb sobre la ciudad de Barcelona desde el 2009 hasta el 2022. En cada observación tenemos un conjunto de características que nos dan información de cómo es el anuncio publicado. Con “nrow()” y “ncol()” podemos ver que tenemos un total de 15778 anuncios con 75 características de cada uno de ellos.
Para este dataset se hará un descarte inicial de variables que no nos harán falta. Algunas de estas, como por ejemplo “description” o “neighborhood_overview” son interesantes si se quiere aplicar un procesamiento de lenguaje natural, pero para este proyecto no nos centraremos en implementar NPL.
Para tener una visión general de los datos podemos utilizar la función “summary()”.
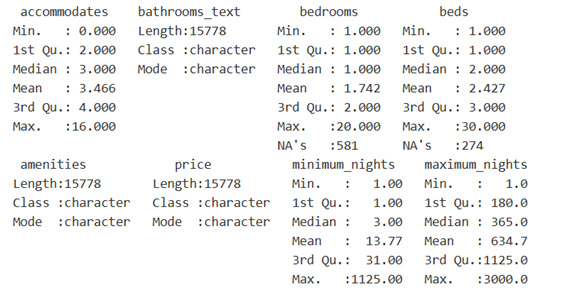
Tal como podemos ver en la imagen de arriba, “summary()” muestra un resumen de todas las variables que tenemos en nuestro data frame (df). En este, podemos ver en el caso de las variables numéricas el valor mínimo, el primer cuartil, la mediana, la media, el tercer cuartil y el valor máximo. Además, para esta clase de atributos se muestran los valores nulos (NA) que pueden tener. En el caso de las variables de caracteres nos muestra simplemente que es un vector de caracteres.
A continuación, se muestran las descripciones de las variables más importantes de nuestro juego de datos. Si quieres ver la información completa de todas ellas, puedes dirigirte a este enlace.
Descripción de las variables
- host_id: identificador único del host.
- host_since: Fecha en la que el usuario/host fue creado.
- neighbourhood_cleansed: Nombre del barrio donde está ubicado el inmueble.
- amenities: Listado de elementos materiales que dispone el inmueble.
- price: Precio de la estancia por persona (en dólares).
- availability_365: Disponibilidad anual del anuncio.
- number_of_reviews: Número total de reseñas que tiene el anuncio.
- reviews_scores_rating: Puntuación total otorgada por los guests.
- reviews_scores_location: Puntuación sobre la localización de la zona donde está el anuncio.
- reviews_per_month: Media de reseñas que tiene el anuncio desde que se publicó.
Con “summary()” hemos visto que algunas características tienen valores nulos. Veamos si además de NA también tienen espacios en blanco o vacíos con:
colSums(airbnb=="" | airbnb== " ")
El resultado es un registro con todas las variables y el número de espacios vacíos o en blanco que tienen cada una de ellas.
Con esta lectura inicial hemos podido hacernos una idea del trabajo que tendremos en la etapa de preprocesamiento.
Objetivo e hipótesis
Antes de esta etapa, deberíamos de tener claro que objetivo debemos perseguir. En muchos casos, este objetivo o necesidad puede darse incluso antes de conocer nuestros datos. Es por este hecho, que el proceso que se sigue en minería de datos se lo suele llamar extracción de conocimiento.
En nuestro caso, nos gustaría encontrar la probabilidad de que un barrio de Barcelona pueda ser susceptible a un incremento de pisos turísticos registrados en Airbnb. Puede ser que necesitemos de datos externos a este dataset, lo cual lo veremos por el camino. Lo que sí que tenemos que tener claro es el porqué del objetivo. En este proyecto, estamos experimentando con unos datos que proporciona Airbnb. Sabemos que el 26 de enero de 2022 entró en vigor el Plan especial urbanístico de alojamientos turísticos (PEUAT). En este Plan se recogen las diferentes áreas en las que se divide Barcelona. En cada una de estas zonas hay unas condiciones que limitan o prohíben el aumento de oferta por parte de Airbnb.
Teniendo en cuenta este Plan urbanístico, nos podemos hacer una idea de que la tendencia de inscripciones en la plataforma de Airbnb irá a la baja. También tenemos que tener en mente que durante estos 13 años hemos vivido una crisis financiera, recesiones y la pandemia. Sabiendo esto, claramente nos podremos imaginar que la probabilidad de que un barrio de BCN sea susceptible al incremento de pisos turísticos inscritos en Airbnb será muy baja. De hecho, esto es lo que esperamos obtener, ya que serían resultados que no se alejan de la realidad de Barcelona.
Así que una vez definido el objetivo, veamos la siguiente etapa.
Preprocesamiento
Esta etapa es la que consume más tiempo de todas, ya que es donde analizamos propiamente las distribuciones de cada variable, si hay inconsistencias, datos sesgados, valores faltantes, errores, etc. y con ello viene la limpieza, transformación, selección de características, normalización (en caso de que así lo requiera el modelo), reducción de la dimensionalidad, etc.
En la lectura inicial del proyecto se han identificado qué variables necesitan ser tratadas y esto nos ayuda a ser más precisos y eficaces en esta etapa. De hecho, esta lectura inicial podría englobarse dentro de las acciones que se realizan dentro del EDA. El preprocesamiento y el análisis exploratorio de los datos se superponen en muchos momentos de estas etapas iniciales. Por eso es recomendable hacer un EDA inicial, preprocesar los datos, seguir con un EDA más exhaustivo, preprocesar en caso de que sea necesario y finalmente terminar con un análisis exploratorio final.
En R, estas etapas se hacen muy amenas por la simplicidad de la sintaxis del código.
Visualización y filtrado de datos
En caso de que queramos ver los datos de toda una columna en concreto, podemos utilizar la siguiente orden:
airbnb$host_sinceEl resultado de esta instrucción es la visualización de todos los valores (string) que conforman “host_since”. En la imagen de abajo se nos muestran los 30 primeros valores.

Pero esto nos mostrará todos los valores de este atributo “host_since”. Se puede ser más preciso y filtrar por lo que queremos ver.
airbnb[airbnb$host_since == "",]Nota: En la imagen de abajo no mostramos todas las características por limitaciones de espacio.
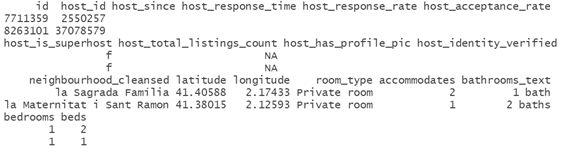
Con el filtro que hemos aplicado nos saldrán todas las filas que cumplen con el filtro especificado en la columna “host_since”. En caso de que se quieran ver solo los valores de esa columna en concreto filtrados podemos hacer:
airbnb$host_since[airbnb$host_since == ""]Al ser casillas sin valor alguno, nos aparecen las dos comillas sin nada en su interior. Esta situación es muy común y puede convertirse en un problema si no se identifica al inicio del proyecto.

Como puedes ver, la sintaxis de R es sencilla y con un poco de práctica, leer un df es mucho más rápido en R que con Excel.
Reducción de características: calcular P(AyB)
Uno de los casos que nos podemos encontrar en esta etapa es la selección de variables, así como intentar reducir el número de características.
En el caso de las variables “host_response_rate” y “host_acceptance_rate” las podemos reducir a una variable. Para ello, jugaremos con la probabilidad.
Sabemos que “host_response_rate” es la tasa de respuesta de mensajes por parte del anfitrión y que “host_acceptance_rate” es la tasa de aceptación del anfitrión hacia un huésped. Por lo tanto, son dos sucesos independientes donde podemos aplicar la probabilidad de que el anfitrión conteste a un mensaje y acepte al huésped.
Probabilidad independiente
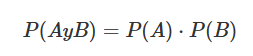
Para ello, lo primero que tendremos que hacer es transformar los valores de estas dos variables a numéricas, ya que tienen el símbolo “%” y esto hace que R lo lea como caracteres.
En la imagen de abajo mostramos los 36 primeros valores de la columna “host_acceptance_rate”. Vemos que son mostrados como caracteres por dos motivos:
– Tienen el símbolo “%”
– Algunas casillas tienen el valor: “N/A”.
Aparte, observamos que algunos valores tienen un “0%”. Puedes ver lo que estamos comentando con la instrucción “airbnb$ host_acceptance_rate”.
Nota: Esta orden imprime por pantalla todos los valores. En la imagen de abajo se muestran los 36 primeros valores por limitaciones de espacio.

Con la función “sub()” se puede utilizar una expresión regular (regex) para substituir este símbolo por el de un espacio vacío. El código sería el siguiente:
airbnb$host_response_rate<-sub("?\\%", "", airbnb$host_response_rate)Con “?\\%” se indica que, en caso de que se encuentre el símbolo “%” en la columna ‘host_response_rate’ se tiene que sustituir por un espacio vacío.
Como se ha observado, hay algunas observaciones sin porcentajes de aceptación o respuesta, o que tienen los caracteres “N/A”. En este caso, se rellenarán o se transformarán estos espacios con la media de cada variable.
mean_response_rate <- mean(as.numeric(airbnb$host_response_rate[!(airbnb$host_response_rate == "N/A" | airbnb$host_response_rate == "" | airbnb$host_response_rate == "0")]))Convertimos aquellos valores NA de host_response_rate en la media de su distribución.
airbnb$host_response_rate[which(airbnb$host_response_rate == "" |
airbnb$host_response_rate == "N/A" | airbnb$host_response_rate == "0")] <- mean_response_rateY ahora sí que podemos convertir estas variables a numéricas y calcular la probabilidad:
airbnb$host_response_rate <- as.numeric(airbnb$host_response_rate)
airbnb$host_acceptance_rate <- as.numeric(airbnb$host_acceptance_rate)Calculamos la probabilidad P(A) · P(B)
airbnb$prob_res_acc <- round(with(airbnb, (host_response_rate/100) * (host_acceptance_rate/100)), 2)Veamos su distribución con:
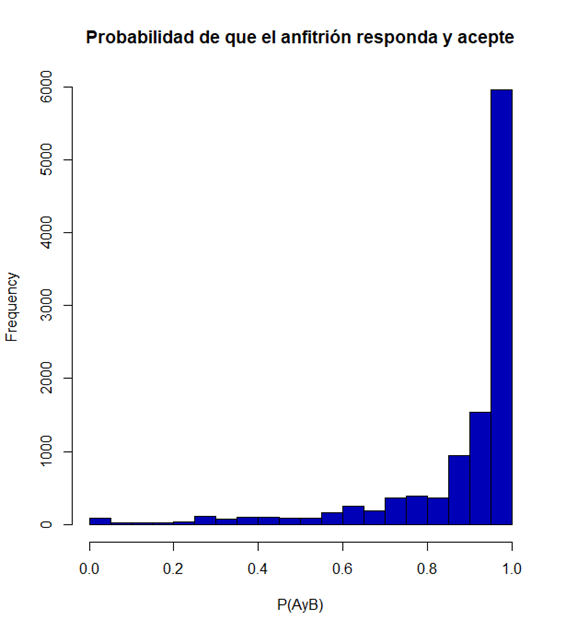
summary(airbnb$prob_res_acc)
Podemos observar que la probabilidad de que el anfitrión responda un mensaje y acepte una solicitud de un huésped es bastante elevada. De hecho, la distribución que vemos marca una clara asimetría hacia la izquierda.
Extraer determinados valores con expresión regular
En el apartado anterior, hemos podido substituir un valor de dentro de un conjunto de caracteres (string) por un espacio vacío con la función “sub()”.
También nos podemos encontrar con que queremos quedarnos con ciertos caracteres y eliminar el resto. En el caso de la variable “bathrooms_text”, pasa lo siguiente:
unique(airbnb$bathrooms_text)
Con “unique()” se pueden ver las categorías únicas de una variable. En este caso, trabajaremos con esta columna, porque la variable “bathrooms” que hemos eliminado al principio solo tenía NA. Así que extraeremos de “bathooms_text”, los valores numéricos de cada string, transformaremos todas aquellas categorías que se pueden reducir en una y convertiremos finalmente la columna a numérica.
Veamos cómo se puede hacer.
Transformamos las siguientes categorías a ‘0.5’.
airbnb$bathrooms_text[which(airbnb$bathrooms_text == "Shared half-bat" | airbnb$bathrooms_text == "Private half-bath" |
airbnb$bathrooms_text == "Half-bath" |
airbnb$bathrooms_text == "0 baths" |
airbnb$bathrooms_text == "" |
airbnb$bathrooms_text == "0 shared baths")] <- "0.5"Extraemos el valor numérico.
airbnb$bathrooms_text <- as.numeric(str_extract(airbnb$bathrooms_text, "[0-9]?[.]?[0-9]"))Substituimos el nombre de la variable por ‘bathrooms
names(airbnb)[13] <- "bathrooms"La expresión regex que hemos usado es “[0-9]?.[.]?[0-9]”. Se ha utilizado dentro de str_extract() para extraer aquellos caracteres que corresponden con la expresión pasada.
[0-9] -> Primero, indicamos que queremos extraer el primer dígito que encuentre.
?.[.] -> Con el interrogante especificamos la posibilidad de que el primer dígito indicado tenga un punto ([.]).
?[0-9] -> Finalmente, indicamos que después del punto, puede que haya otro dígito.
En el caso de que coincida la expresión con algún conjunto de caracteres de cada string, se extraerá el valor numérico. Como puedes ver, en nuestro código hemos realizado dos funciones en la misma línea: primero “str_extract()” y después “as.numeric()”. El resultado lo hemos guardado directamente en la misma variable “bathrooms_text”. Es decir, hemos actualizado la columna de character a numeric con los valores numéricos.
Agregar y obtener la media de reseñas por barrio
Seguimos con la selección y reducción de variables.
Hemos visto que tenemos una variable con el total de reseñas por mes que recibe cada anuncio. En nuestro caso, nos interesa obtener la media de reseñas de cada barrio para así saber cuáles son los más elegidos. Para hacer este cálculo usaremos “aggregate()” y “merge()”.
average_reviews_neighb <- as.data.frame(aggregate(airbnb$reviews_per_month, by=list(Category=airbnb$neighbourhood_cleansed), FUN=mean))Redondeamos los valores de la columna agregada a 2 decimales.
average_reviews_neighb$x <- round(average_reviews_neighb$x, 2)Substituimos el nombre de las variables del df creado.
names(average_reviews_neighb)[1:2] <- c("neighbourhood_cleansed", "average_reviews_neighb")Hacemos merge() para unir la columna ‘average_reviews_neighb’ a airbnb.
airbnb <- merge(airbnb, average_reviews_neighb, by="neighbourhood_cleansed", all.x = TRUE)
summary(airbnb$average_reviews_neighb)Con la última instrucción vemos un resumen estadístico de la columna tratada.

Observamos que la diferencia entre la mediana y la media es muy baja. De hecho, si calculamos el rango intercuartílico, podemos ver que el 50% de los datos se encuentran en un rango de 0.19 puntos respecto el valor del primer y del tercer cuartil.
IQR(airbnb$average_reviews_neighb)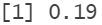
Obtener la valoración sobre la localización del inmueble
Hemos constatado que hay 25 observaciones con NA en la columna de “review_socres_location”.
length(airbnb$id[is.na(airbnb$review_scores_location)])
En este caso, se podría calcular la media de puntuación de cada barrio y colocárselo a cada observación que tengan NA. No obstante, ya que tenemos a disposición la API de OpenStreetMap para sacar información geográfica de cualquier sitio, haremos lo siguiente:
– Obtendremos los elementos que configuran el entorno del inmueble en un radio de 500 m. Seguidamente, valoraremos con más puntuación aquellas áreas que dispongan de estaciones de tren/bus/metro y atracciones y con menos puntuación a los supermercados, cafés, restaurantes y parkings. La valoración máxima que podrá tener un inmueble es de 3 puntos.
– Aparte de tener en cuenta los elementos tangibles que configuran el entorno del inmueble, calcularemos el índice de vegetación (NDVI). Aquellas zonas con más de 0.30 de NDVI tendrán 2 puntos; entre 0.20 y 0.30 tendrán 1 punto y menos de 0.20 tendrán 0.5 puntos. Es importante remarcar que la puntuación en general del NDVI es baja, ya que estamos ubicados en zona urbana.
Para obtener la puntuación del primer punto desarrollaremos una función que calcula la puntuación teniendo en cuenta lo que hemos detallado anteriormente. Según las coordenadas de cada anuncio extraemos la información requerida para hacer la valoración.
Si quieres entender mejor el código puedes mirar el proyecto de GitHub y también este post donde se explican diferentes métodos de obtener información con OSM, entre ellos la función que hemos implementado en este proyecto.
Discretizar los valores de NDVI
Por lo que respecta al NDVI, es interesante ver la media del índice de vegetación de cada área alrededor de cada inmueble turístico. Veamos el código:
ndvi = raster("data/ndvi_2019.tif")
plot(ndvi, main= "NDVI de Barcelona (2019)")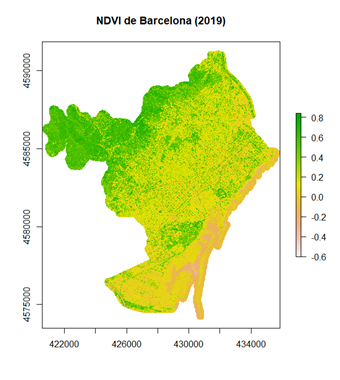
Primeramente, cargamos los datos que han sido descargados de este enlace. En la imagen de arriba hemos renderizado los valores de NDVI de BCN. Vemos que en las zonas más urbanas los valores son bastante bajos.
A continuación, utilizaremos los dados geolocalizados que no tienen valoración y que están almacenados en el df “nanLocation”. El primer paso será convertir cada geometría de Standard Spatial Type (ST) a Simple Feature (SF). Seguidamente transformaremos las coordenadas de grados a decimales con EPSG: 25831.
dt <- st_as_sf(nanLocation, coords = c("longitude","latitude"), crs = 4326)Transformamos grados a decimales.
ndvitrans <- st_transform(dt, 25831)En las siguientes líneas crearemos una nueva columna correspondiente a la puntuación respecto la media de NDVI de cada área, donde su centroide será el punto geolocalizado del inmueble turístico.
Creamos la columna ndvi.
nanLocation$ndvi <- NAIteramos por los puntos (inmuebles). Le aplicamos un buffer de 500 m y extraemos el valor medio del raster (ndvi). Por último, pasamos los valores a la columna ndvi.
for (i in 1:nrow(ndvitrans)){
buffer_geom <- st_buffer(ndvitrans[i,], dist = 500)
value <- round(extract(ndvi, st_as_sf(buffer_geom), fun=mean, na.rm=TRUE), 2)
nanLocation$ndvi[i] <- valueDiscretizamos los valores del NDVI para otorgarle una puntuación.
nanLocation$scoreNdvi <- ifelse(nanLocation$ndvi >= 0.10 &
nanLocation$ndvi < 0.20, 0.5,
ifelse(nanLocation$ndvi >= 0.20 &
nanLocation$ndvi <= 0.30, 1, 2))Sumamos la puntuación final.
nanLocation$totalScore <- with(nanLocation, elementScore + scoreNdvi)
airbnb$review_scores_location <- ifelse(is.na(airbnb$review_scores_location), nanLocation$totalScore, airbnb$review_scores_location)
Finalmente, vemos un resumen estadístico de la variable “review_scores_location”.
summary(airbnb$review_scores_location)
Si lo comparamos con el resumen estadístico de este atributo antes de realizar este proceso vemos que los indicadores no se han desplazado mucho.
summary(df$review_scores_location)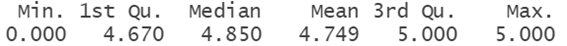
Conclusiones
En esta primera parte hemos realizado una lectura previa de los datos, para luego poder transformar, limpiar y discretizar los datos con mayor precisión. Hemos visto diferentes procesos que nos ayudan a conseguir unos datos más claros y así poder extraer el conocimiento más eficientemente.
Por el momento hemos visto que muchas de las características presentan valores nulos o espacios vacíos, además de un sesgo importante.
Hasta ahora hemos trabajado con algunas características que presentan NA y hemos limpiado y depurado los datos.
En esta etapa todavía no podemos extraer conclusiones sólidas sobre los datos porque nos falta hacer un análisis exploratorio exhaustivo para poder comprender la historia que se esconde detrás de ellos.
En la siguiente parte, realizaremos la parte final del preprocesamiento y realizaremos el EDA con el que podremos entender mucho mejor la información que hay almacenada en este juego de datos.
Puedes consultar el proyecto completo en este enlace.