
17 Jul 2017 Cómo consolidar datos de una API en una base de datos
Gracias a la apertura de datos públicos por parte de las administraciones, se han ampliado en gran medida las posibilidades de analizar todo tipo de datos geoespaciales que hasta hace bien poco no estaban disponibles.
En este ejercicio vamos a analizar la actividad del bicing a lo largo de un periodo de tiempo. Para ello vamos a utilizar los datos del servicio público de bicicletas (bicing) de la ciudad de Barcelona disponibles en el portal de Open Data del Ajuntament de Barcelona (http://opendata-ajuntament.barcelona.cat/data/es/dataset/bicing).
Estos datos se actualizan continuamente y permiten, más allá de cartografiar las estaciones, poder analizar en tiempo real el uso que hacen los ciudadanos de la bicicleta: en qué estaciones hay mayor actividad, dónde se cogen más bicicletas en un determinado momento, qué diferencias hay entre dias laborables y festivos… Datos que permitirían ser analizados o visualizados a través de un mapa y de forma dinámica.
La información que nos da este servicio, es un json con el id, las coordenadas (latitud/longitud), la dirección, el número de bicicletas y párkings disponibles de cada estación de la ciudad.
{
«id«: «1»,
«type«: «BIKE»,
«latitude«: «41.397952»,
«longitude«: «2.180042»,
«streetName«: «Gran Via Corts Catalanes»,
«streetNumber«: «760»,
«altitude«: «21»,
«slots«: «14»,
«bikes«: «1»,
«nearbyStations«: «24, 369, 387, 426»,
«status«: «OPN»
},
Ejemplo de la información de la estación con el id 1 que nos retorna el json.
Sin embargo, antes de proceder al análisis y visualización de estos datos debemos consolidarlos de algún modo en un archivo o base de datos. Hay que tener presente que el servicio web del que disponemos es un json que se actualiza continuamente, y por lo tanto no nos ofrece ningún histórico de estos datos.
¿Dónde almacenamos los datos?
Para almacenar los datos que estamos recogiendo podríamos elegir entre muchísimas posibilidades. En este caso, vamos a utilizar el sistema gestor de bases de datos PostgreSQL, que podemos instalar en sistemas operativos tanto Windows, Linux como Mac.
Con PostgreSQL instalado, vamos a crear la tabla en la que insertar los datos:
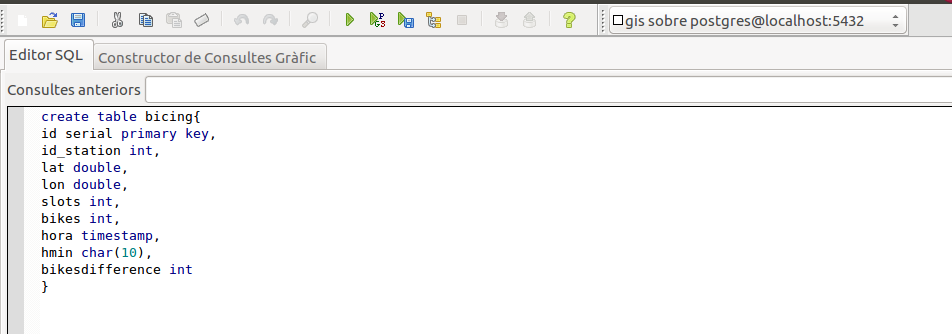
¿Cómo capturamos los datos?
Los datos se capturan utilizando un script de python, ya que nos resultará relativamente fácil acceder a los datos del bicing del servicio web que comentamos anteriormente.
En el repositorio de github https://github.com/josepsitjar/bicing se puede encontrar un ejemplo de script (bicing.py) que permite estas tareas:
- Acceder a los datos del bicing en formato json
- Insertar estos datos a la tabla de PostgreSQL que hemos creado. Es importante tener en consideración el hecho de cambiar los parámetros de conexión a la base de datos (usuario y contraseña).
¿Cómo programar una tarea para ir insertando los datos?
La ejecución del script anterior permite insertar los datos en un momento determinado. Para que esta tarea se vaya repitiendo y por lo tanto, vayamos almacenando datos consecutivamente, podemos utilizar crontab (en sistemas operativos Liux).
Lo primero que debemos hacer es acceder al fichero de tareas de crontab. Para ello accederemos tecleando en la terminal el comando $crontab -e
Si queremos obtener datos de cada minuto, es decir, que el script se vaya ejecutando cada minuto, deberemos añadir al documento de tareas de crontab lo siguiente:
*/1 * * * * /usr/bin/python /direcotrio del script/bicing.py
Una vez introducida la tarea se puede salir y guardar los cambios. De forma automática el sistema operativo irá ejecutando el script. Para comprobar que funciona correctamente se puede consultar la base de datos y ver si se van insertando nuevos registros.
Para entender cómo funciona el crontab y como configurarlo, os recomiendo la siguiente lectura:
https://help.ubuntu.com/community/CronHowto
Para los usuarios de windows, se recomienda consultar este documento.
https://technet.microsoft.com/en-us/library/cc766428(v=ws.11).aspx¡
Próximos pasos
Hasta ahí hemos conseguido consolidar los datos en tiempo real del bicing en nuestra base de datos (hay que tener presente que la inserción de datos se ejecuta hasta que cancelemos el cron).
Sin embargo, uno de los datos que necesitamos para determinar la actividad en cada estación, es la diferencia de bicis disponibles entre dos momentos consecutivos. Ello nos permitirá saber si hay muchos usuarios cogiendo bicis, o por el contrario, nadie está utilizando las bicis de una determinada estación. Sin embargo, esta información no viene en el servicio web del bicing de modo que debemos extraerla nosotros mismos.
Seguramente existen diversas estrategias para ello. En un próximo post vamos a exponer un método basado en programar una pequeña función y un trigger en PostgreSQL para que cada vez que se inserten nuevos datos de una estación se compruebe la disponibilidad de bicis en la misma justo en el insert anterior.